本ページは、AWS に関する個人の勉強および勉強会で使用することを目的に、AWS ドキュメントなどを参照し作成しておりますが、記載の誤り等が含まれる場合がございます。
最新の情報については、AWS 公式ドキュメントをご参照ください。
Amazon Kinesis Data Streams は、リアルタイムでストリーミングデータを収集、処理、分析できるフルマネージドサービスです。大量のデータを毎秒数千から数百万のレコードレベルで、複数のソースから継続的に収集し、リアルタイムでの処理を可能にします。
1.1. 公式ドキュメント
Amazon Kinesis Data Streamsを理解する公式ドキュメントは次のとおりです。
Amazon Kinesis Data Streams サービス概要
Amazon Kinesis Data Streams ドキュメント
Amazon Kinesis Data Streams よくある質問
Amazon Kinesis Data Streams の料金
1.2. 学習リソース
【AWS Black Belt Online Seminar】Amazon Kinesis(pdf)

「Amazon Kinesis Data Streams」をグラレコで解説|builders.flash
1.3. ワークショップ
Real Time Streaming with Amazon Kinesis
ストリーミングデータをニアリアルタイムに取得し分析するソリューションを試す|builders.flash
ドキュメントには、以下の入門チュートリアルがあります。
- チュートリアル: KPL と KCL 2.x を使用して株式データをリアルタイム処理する
- チュートリアル: KPL と KCL 1.x を使用して株式データをリアルタイム処理する
- チュートリアル: Amazon Managed Service for Apache Flink を使用してリアルタイムの株式データを分析する
- チュートリアル: Amazon Kinesis Data Streams AWS Lambda で を使用する
- Amazon Kinesis AWS のストリーミングデータソリューションを使用する
1.4. 導入のメリット
Kinesis Data Streamsを導入する主なメリットは以下の5つです。
- リアルタイム処理: ミリ秒単位の低レイテンシでデータを処理し、リアルタイム分析やアプリケーションを構築
- 高い耐久性: データは複数のAZに複製され、24時間から最大365日まで保持可能
- 高いスケーラビリティ: 秒間数百万のレコードまでスケールアップ可能
- フルマネージド: インフラストラクチャの管理が不要で、AWS側でメンテナンスを実施
- セキュリティ: 転送中および保存時の暗号化、IAMベースのアクセス制御をサポート
1.5. 主なユースケース
- リアルタイム分析: ウェブサイトのクリックストリーム分析、IoTセンサーデータの分析
- ログとイベントデータの収集: アプリケーションログの集約、システムメトリクスの収集
- リアルタイム機械学習: 不正検知、推奨システム、異常検知
- データパイプライン: ETLパイプラインのリアルタイム版、データウェアハウスへの継続的なデータ投入
- リアルタイム通知: アラート、通知システム
2.1. アーキテクチャ概要
Kinesis Data Streamsは以下の主要コンポーネントで構成されています。

基本的なデータフロー:
- プロデューサーがデータレコードをストリームに送信
- データはシャードに分散して格納
- コンシューマーがシャードからデータを読み取り
- データは設定された保持期間内で利用可能
2.2. シャード
シャードは、Kinesis Data Streamの基本的なスケーリング単位です。

シャードの特徴:
- 各シャードは1秒間に1MBまたは1,000レコードまでの書き込みをサポート
- 各シャードは1秒間に2MBまでの読み取りをサポート(最大5トランザクション/秒)
- データは最大24時間から365日まで保持可能(デフォルト24時間)
- パーティションキーによってデータがシャードに分散される
- シャードごとにシーケンス番号によって順序が保証されるが、ストリーム全体での順序番号ではないので区別するにはパーティションキーか、データセットごとにストリームを分ける
シャード管理:
- リシャーディング: シャード分割(SplitShard)やマージ(MergeShards)による容量調整
- オートスケーリング: On-Demandモードまたは自動スケーリング設定による動的調整
- デフォルトクォータ: US East (N. Virginia)、US West (Oregon)、Europe (Ireland)では20,000シャード/ストリーム、その他のリージョンでは1,000または6,000シャード/ストリーム
2.3. データレコード
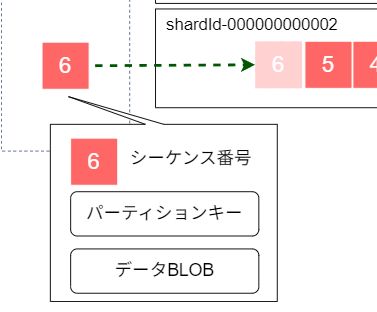
データレコードは以下の要素で構成されます。
- パーティションキー: データの分散を決定するキー(最大256文字)
- データBLOB: 実際のデータ(最大1MB)
- シーケンス番号: Kinesisが自動的に割り当てる一意識別子
2.4. プロデューサー
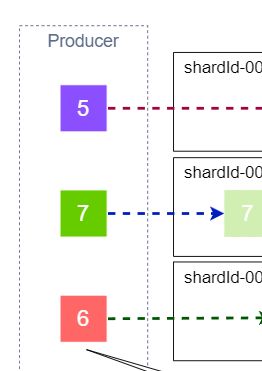
データをストリームに送信するアプリケーションまたはサービスです。
プロデューサーの種類は次のようなものがあります。
- Kinesis Producer Library (KPL): 高スループット向けライブラリ
- AWS SDK: 様々なプログラミング言語でのAPI呼び出し
- Kinesis Agent: ログファイルを監視して自動送信
- サードパーティツール: Fluentd、Apache Kafkaなど
- AWSサービス: AWSサービスから直接送信
Pythonを使用した送信方法(put_record)の例:
import boto3
kinesis = boto3.client('kinesis')
response = kinesis.put_record(
StreamName='my-stream',
Data=json.dumps(data),
PartitionKey='partition-key'
)
# response
#{
# "ShardId": "shardId-000000000000",
# "SequenceNumber": "49546986683135544286507457936321625675700192471156785154"
#}
2.5. コンシューマー
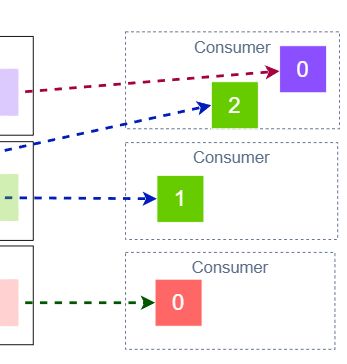
ストリームからデータを読み取り、処理するアプリケーションです。
コンシューマーの種類は次のようなものがあります。
- Kinesis Client Library (KCL): 複数インスタンスでの並列処理
- AWS Lambda: サーバーレスでのイベント処理
- Kinesis Data Firehose: S3、Redshift等への配信
- Managed Service for Apache Flink(旧Kinesis Data Analytics) : Java、Scala、Python、または SQL を使用してストリーミングデータを処理および分析
Pythonを使用したデータ取得方法(get_records)の例:
import boto3
kinesis = boto3.client('kinesis')
shard_iterator = kinesis.get_shard_iterator(
StreamName='your-stream-name',
ShardId=shard_id,
ShardIteratorType='LATEST'
)
while True:
records = kinesis.get_records(ShardIterator=shard_iterator, Limit=100)
for record in records['Records']:
:
shard_iterator = records['NextShardIterator']
# NextShardIteratorがNoneの場合
if shard_iterator is None:
break
# response
#{
# 'Records': [
# {
# 'SequenceNumber': 'string',
# 'ApproximateArrivalTimestamp': datetime(2015, 1, 1),
# 'Data': b'bytes',
# 'PartitionKey': 'string',
# 'EncryptionType': 'NONE'|'KMS'
# },
# ],
# 'NextShardIterator': 'string',
# :
#}
コンシューマーのタイプは次のようなものがあります。

- 共有スループットコンシューマー(Shared-Throughput Consumer): 複数のコンシューマーでシャードの読み取り容量(2MB/秒)を共有
- 拡張ファンアウトコンシューマー(Enhanced Fan-Out Consumer): 専用の読み取り容量を持つコンシューマー(各コンシューマーが2MB/秒の専用スループット)
AWS CLI(register-stream-consumer)で拡張ファンアウトコンシューマーを追加する例:
aws kinesis register-stream-consumer \
--stream-arn arn:aws:kinesis:ap-northeast-1:123456789012:stream/stream-name \
--consumer-name SampleDataStreamConsumer
2.6. データストリーム容量モード
データストリームの容量の管理方法と、データストリームの使用に対する課金方法を決定します。 データストリームのオンデマンドモードとプロビジョンドモードのどちらかを選択できます。
また、 AWS アカウントのデータストリームごとに、オンデマンド容量モードとプロビジョンド容量モードを 24 時間で 2 回切り替えることができます。
- Provisioned Mode(プロビジョンドモード)
- 手動でシャード数を管理
- 予測可能なワークロードに適している
- コスト効率が良い
- On-Demand Mode(オンデマンドモード)
- AWS が自動的にシャードを管理
- 予測不可能なワークロードに適している
- 運用負荷が少ない
AWS CLIの使用例:
aws kinesis update-stream-mode \
--stream-arn arn:aws:kinesis:ap-northeast-1:123456789012:stream/stream-name \
--stream-mode-details ON_DEMAND
2.7. 料金体系
Provisioned Mode:
- シャード時間: 1シャード時間あたり $0.0195
- PUT Payload Unit: 100万PUT Payload Unitあたり $0.0215(25KBずつカウント)
- 拡張データ保持期限 (最大 7 日間): 1GBあたり $0.026
On-Demand Mode:
- ストリーム時間: 1ストリーム時間あたり $0.052
- データ書き込み: 1GBあたり $0.104
- データ読み取り: 1GBあたり $0.052
- データ保持 (~7 日間): 1GBあたり $0.012
- データ保持 (7 日間が経過した後): 1GBあたり $0.0025
3.1. サーバーサイド暗号化
Kinesis Data Streamsは保存時暗号化をサポートしています。
暗号化オプションは次のとおりです。
- AWS管理キー: AWSが管理するキーによる暗号化
- 顧客管理キー: AWS KMSで管理するカスタマーキー
aws kinesis create-stream --stream-name Foo \
--shard-count 3
--stream-mode-details PROVISIONED
aws kinesis start-stream-encryption \
--encryption-type KMS \
--key-id arn:aws:kms:us-west-2:012345678912:key/a3c4a7cd-728b-45dd-b334-4d3eb496e452 \
--stream-name Foo
3.2. Kinesis Scaling Utility
オープンソースのスケーリングユーティリティです。「GitHub>awslabs>amazon-kinesis-scaling-utils」で公開されています。
基本機能:
- 手動スケーリング: コマンドラインから実行可能で、EC2 Auto Scalingグループと同様の方式でスケールアップ・スケールダウンが可能
- 自動スケーリング: CloudWatch統計を監視し、PUT率やGET率に基づいて自動的にシャード数を調整
3.3. Kinesis Client Library (KCL)
複数インスタンスでの分散処理を簡単にするライブラリです。
KCLの特徴:
- 負荷分散: 複数のワーカー間でシャードを自動分散
- フェイルオーバー: ワーカー障害時の自動復旧
- チェックポイント: 処理済みレコードの追跡
KCL for Pythonの実装例:
from amazon_kclpy import kcl
class RecordProcessor(kcl.RecordProcessorBase):
def process_records(self, process_records_input):
for record in process_records_input.records:
# レコード処理ロジック
data = record.binary_data
# ビジネスロジック実装
:
# チェックポイント作成
if time.time() - self._last_checkpoint_time > self._CHECKPOINT_FREQ_SECONDS:
self.checkpoint(process_records_input.checkpointer, str(self._largest_seq[0]), self._largest_seq[1])
self._last_checkpoint_time = time.time()
3.4. 他のAWSサービスとの統合
主な統合パターン:
- Lambda: サーバーレスでのリアルタイム処理
- Kinesis Data Firehose: S3、Redshift、OpenSearchへの配信
- Managed Service for Apache Flink(旧Kinesis Data Analytics) : Java、Scala、Python、または SQL を使用してストリーミングデータを処理および分析
- EMR: 大規模データ処理
- CloudWatch: メトリクス監視とアラート
Lambdaで実装した場合の例:
# Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
# SPDX-License-Identifier: Apache-2.0
import base64
def lambda_handler(event, context):
for record in event['Records']:
try:
print(f"Processed Kinesis Event - EventID: {record['eventID']}")
record_data = base64.b64decode(record['kinesis']['data']).decode('utf-8')
print(f"Record Data: {record_data}")
# TODO: Do interesting work based on the new data
except Exception as e:
print(f"An error occurred {e}")
raise e
print(f"Successfully processed {len(event['Records'])} records.")
CloudFormationでのLambda統合例:
LambdaFunction:
Type: AWS::Lambda::Function
Properties:
EventSourceMappings:
- EventSourceArn: !GetAtt KinesisStream.Arn
StartingPosition: TRIM_HORIZON | LATEST | AT_TIMESTAMP
BatchSize: 100 # 最大レコード数
4.1. コスト管理
コスト最適化戦略:
- 適切なモードを選択する
- 予測可能なワークロード → Provisioned Mode
- 変動の大きいワークロード → On-Demand Mode
- シャードを最適化する: 必要最小限のシャード数で運用
- データ保持期間を最適化する: 必要な期間のみ設定(デフォルト24時間)
- Enhanced Fan-Outの使用を検討する: 必要な場合のみ使用
4.2. モニタリング
重要なメトリクス:
- IncomingRecords: Kinesis ストリームが受信したレコード数
- IncomingBytes: Kinesis ストリームが受信したバイト数
- OutgoingRecords: Kinesis ストリームが送信したレコード数
- GetRecords.IteratorAgeMilliseconds: 最古レコードの経過時間(ミリ秒)※
GetRecords.IteratorAgeは使用されなくなりました - WriteProvisionedThroughputExceeded: 書き込み制限超過が発生した数
- ReadProvisionedThroughputExceeded: 読み取り制限超過が発生した数
- PutRecord.Success、PutRecords.Success: PutRecordが成功した数
AWS CLIでのアラート設定例:
# CloudWatchアラーム設定
aws cloudwatch put-metric-alarm \
--alarm-name "Kinesis-ReadProvisionedThroughputExceeded-Alarm" \
--alarm-description "Kinesisストリームで読み取りスループット制限を超過した場合のアラーム" \
--metric-name ReadProvisionedThroughputExceeded \
--namespace AWS/Kinesis \
--statistic Sum \
--period 300 \
--threshold 1 \
--comparison-operator GreaterThanThreshold \
--evaluation-periods 1 \
--alarm-actions arn:aws:sns:ap-northeast-1:123456789012:kinesis-alerts \
--dimensions Name=StreamName,Value=your-stream-name \
--region ap-northeast-1
4.3. セキュリティ
セキュリティベストプラクティス:
- 暗号化: 保存時・転送時暗号化の有効化
- アクセス制御: IAMポリシーによる最小権限の原則
- VPCエンドポイント: プライベートネットワーク経由でのアクセス
- ログ監査: CloudTrailによるAPI呼び出しの記録
IAMポリシー例:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kinesis:PutRecord",
"kinesis:PutRecords"
],
"Resource": "arn:aws:kinesis:region:account:stream/my-stream"
},
{
"Effect": "Allow",
"Action": [
"kinesis:GetRecords",
"kinesis:GetShardIterator",
"kinesis:DescribeStream",
"kinesis:ListStreams"
],
"Resource": "arn:aws:kinesis:region:account:stream/my-stream"
}
]
}
4.4. パフォーマンス最適化
スループット最適化:
- パーティションキー分散: ホットパーティション回避
- バッチ処理: PutRecordsでのバッチ送信
- 適切なシャード数: ワークロードに応じたスケーリング
- コンシューマー最適化: Enhanced Fan-Outの活用
Amazon Kinesis Data Streams は、リアルタイムストリーミングデータ処理のための強力なサービスとして以下の価値を提供します。
- リアルタイム処理: 低レイテンシでの大量データ処理により、即座の意思決定をサポート
- 高い可用性: マルチAZ冗長化と自動フェイルオーバーによる継続的なサービス提供
- 柔軟なスケーリング: On-DemandモードとProvisionedモードによる最適な容量管理
- 豊富な統合: AWSエコシステム内の他サービスとのシームレスな連携
- セキュリティ: 暗号化とアクセス制御による企業レベルのデータ保護
リアルタイムデータ分析、IoTデータ処理、ログ集約など、ストリーミングデータを扱うシステムを構築する際は、Kinesis Data Streamsを検討しましょう。特に高スループット・低レイテンシが要求されるアプリケーションにおいて威力を発揮します。