本ページは、AWS に関する個人の勉強および勉強会で使用することを目的に、AWS ドキュメントなどを参照し作成しておりますが、記載の誤り等が含まれる場合がございます。
最新の情報については、AWS 公式ドキュメントをご参照ください。
抽出、変換、ロード (ETL) プロセスの検出、準備、統合、近代化(モダナイゼーション)を容易にするサーバーレスデータ統合サービスです。
近代化(モダナイゼーション)とは、単にツールを新しくするだけでなく、データ統合のプロセス全体をよりスケーラブルで、管理しやすく、コスト効率の良いものに変革することを意味し、AWS Glueは、これらの「近代化」を実現するためのマネージドサービスです。
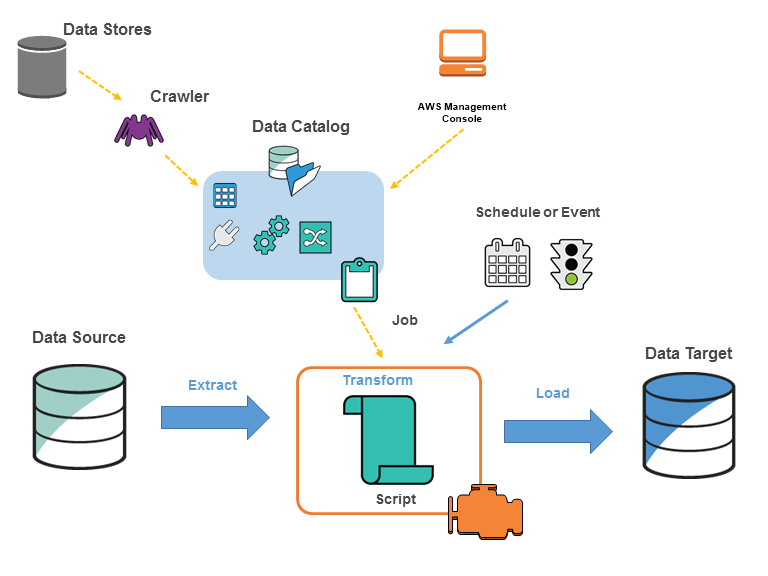
(引用元:AWS Glue の概念)
1.1. 公式ドキュメント
AWS Glueを理解する公式ドキュメントは次のとおりです。
1.2. 学習リソース
【AWS Black Belt Online Seminar】AWS Glue(YouTube)(0:55:30)

AWS Glue【AWS Black Belt】(0:41:53)

[AWS Black Belt Online Seminar]猫でもわかる、AWS Glue ETLパフォーマンス・チューニング 基礎知識編(0:34:22)

[AWS Black Belt Online Seminar]猫でもわかる、AWS Glue ETLパフォーマンス・チューニング 後編(0:34:47)

【AWS Black Belt Online Seminar】AWS Glue -Glue Studioを使ったデータ変換のベストプラクティス-(0:57:13)

【AWS Black Belt Online Seminar】AWS Glue DataBrew(0:56:49)

1.3. ワークショップ
- AWS Glue DataBrew Immersion Day
- Data Engineering Immersion Day
- HOL-01:AWS ではじめるデータ分析〜データレイクハンズオン〜
- Amazon Personalize with Glue DataBrew
1.4. Glue導入のメリット
AWS Glueを導入する主なメリットは以下の3つです。
- サーバーレス
- インフラ構築・管理が不要
- 必要な時に分析環境を使用可能
- スケーラブルな処理基盤
- 運用負荷の軽減
- ETLに必要な機能が標準機能を利用可能
- データ分析環境や処理の更新が容易
- 自動化による保守性の向上
- ビジネス価値への集中
- ETLが自動化によりデータ分析に専念
- データサイエンティストの生産性向上
1.4. 主なユースケース
- データレイク構築
- データウェアハウス連携
- バッチ処理の自動化
Glueの主要な機能は次のとおりです。
- データカタログ
- クローラー
- ETLジョブ
- Glue Studio
- ワークフロー
2.1. データカタログ
データの場所やスキーマといったメタデータ管理する機能です。
データカタログは、データベースとテーブルというオブジェクトから構成されます。データベースは、データカタログを論理的にグループ化したものと言えます。 例えば、次のようなグループ化の方法があります。
- データ環境別のグループ化
- raw_database: 生データ
- staging_database: 加工途中のデータ
- analytics_database: 分析用に整形済み
- ビジネス部門別のグループ化
- sales_database: 営業部門のデータ
- marketing_database: マーケティング部門のデータ
- finance_database: 経理部門のデータ
テーブルは、データの場所やスキーマの情報が格納されています。 実際に格納されている情報はマネジメントコンソールで確認できます。 CloudTrailが出力したログのテーブルは次のようになっています。
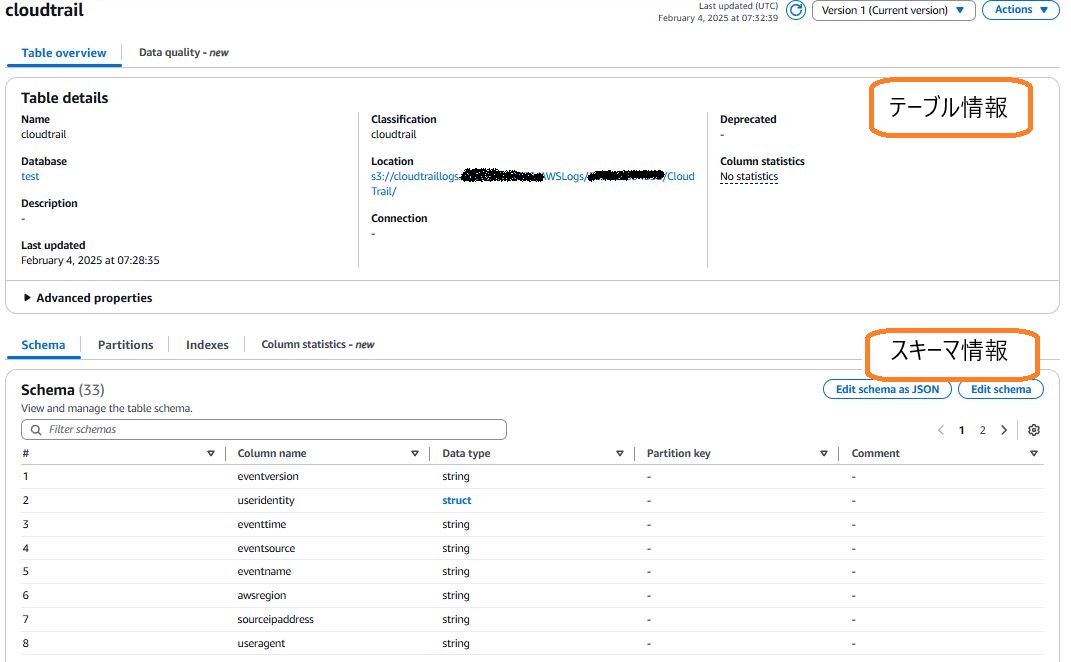
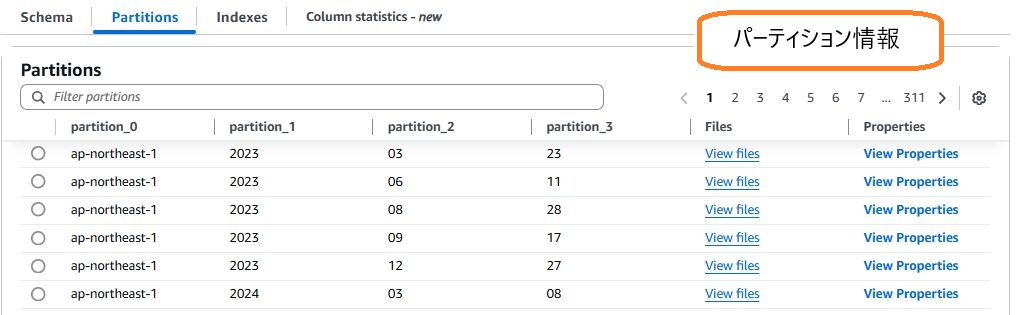

テーブルはバージョン管理されていて、過去のバージョンとの比較もできます。
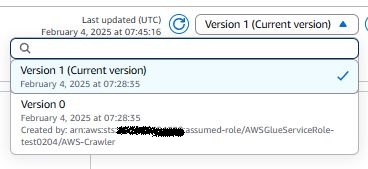
コンソールでのバージョン比較はこのように確認できます。
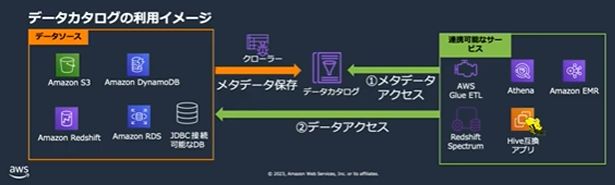
データカタログを利用できるAWSサービスは次のようなものがあります。
- Amazon Athena
- Amazon Redshift Spectrum
- Amazon EMR
- Apach Hiveメタストア
データカタログの利用イメージ(引用:Blackbelt)
2.2. クローラー
メタデータをデータカタログに登録・更新する機能です。 定期的に実行することで、スキーマの自動更新が可能になります。
スケジュールは、オンデマンドで実行するか、定期的に実行するかを選択できます。 Hourlyなど簡単な設定方法や、cron形式で詳細な実行スケジュールを作成することもできます。
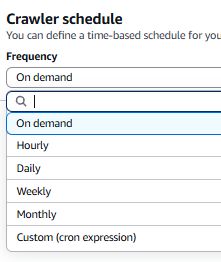
クローラーを定期的に実行させることで、新しいデータやスキーマの変更を検知できます。
クローラーが取得可能なデータソースは、ドキュメントによると次のようなものがあります。
- ネイティブクライアント
- Amazon S3
- Amazon DynamoDB
- Delta Lake
- Apache Iceerg
- Apache Hudi
- JDBC
- Amazon Redshift
- Snowflake
- Amazon Aurora
- MariaDB
- Microsoft SQL Server
- MySQL
- PostgreSQL
- Oracle
- MongoDB クライアント
- MongoDB
- Amazon DucumentDB
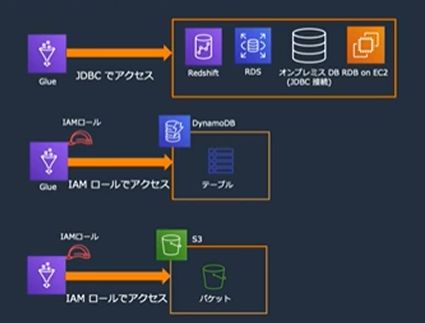
標準でサポートしていないデータソースは、AWS Marketpkaceから取得するか、独自でカスタムコネクタを作成することができます。
2.3. ETLジョブ
ジョブとは、データソースに接続してデータターゲットに出力する処理を実行するものです。
ジョブの種類は以下のとおりです。
- Sparkジョブ
- Apache Sparkを利用した大規模なバッチデータ処理向け
- Pythonシェルジョブ
- Pythonスクリプトを実行でき、分散処理を必要としない軽量な処理向け
- ストリーミングETLジョブ
- Amazon Kinesis Data StreamsやAmazon MSKなどのストリーミングソースから連続的に実行されるジョブ
- Rayジョブ
- Pythonワークロードを実現可能なOSSのRayを用いたマルチノード環境で高速に処理できる
- Sparkよりも低い学習コストで、既存のPythonコードを並列化することも容易
※15分以内に処理が完了でき、小規模な処理であればAWS Lambdaの利用も検討する。
2.3.1. DPU とワーカー
ジョブには、DPU とワーカーというものがあります。
- DPU: Data Processing Unit
- ジョブに割り当てる処理能力の単位で、1DPUにつき4vCPUと16GBのメモリ
- 1時間あたりに決められた料金が1秒単位で課金される
- 1DPU = 0.44USD/時で、6DPUを15分利用した場合、6DPU×0.44×0.25時間=0.66USD
- ワーカータイプによって、1分or10分の最低料金がある
- ワーカー
- SparkジョブとRayジョブで指定できる事前定義済みのワーカー
- ワーカータイプ
- G.025X=0.25DPU、標準=1DPU、G.1X=1DPU、G.2X=2DPU、G.4X=4DPU、G.8X=8DPU
- 多くのメモリが必要なら大きいワーカータイプを選択する。
- ワーカー数
- これを増やすと分散実行数が増える
- 1つのワーカー内には、Executorという処理を実行する1つ存在する
- 標準タイプのワーカーには、Executorが2つ存在する。その分、1つのExecutorが利用できるメモリが減る
- 並列性が求められる場合は、ワーカー数を増やす
2.4. Glue Studio
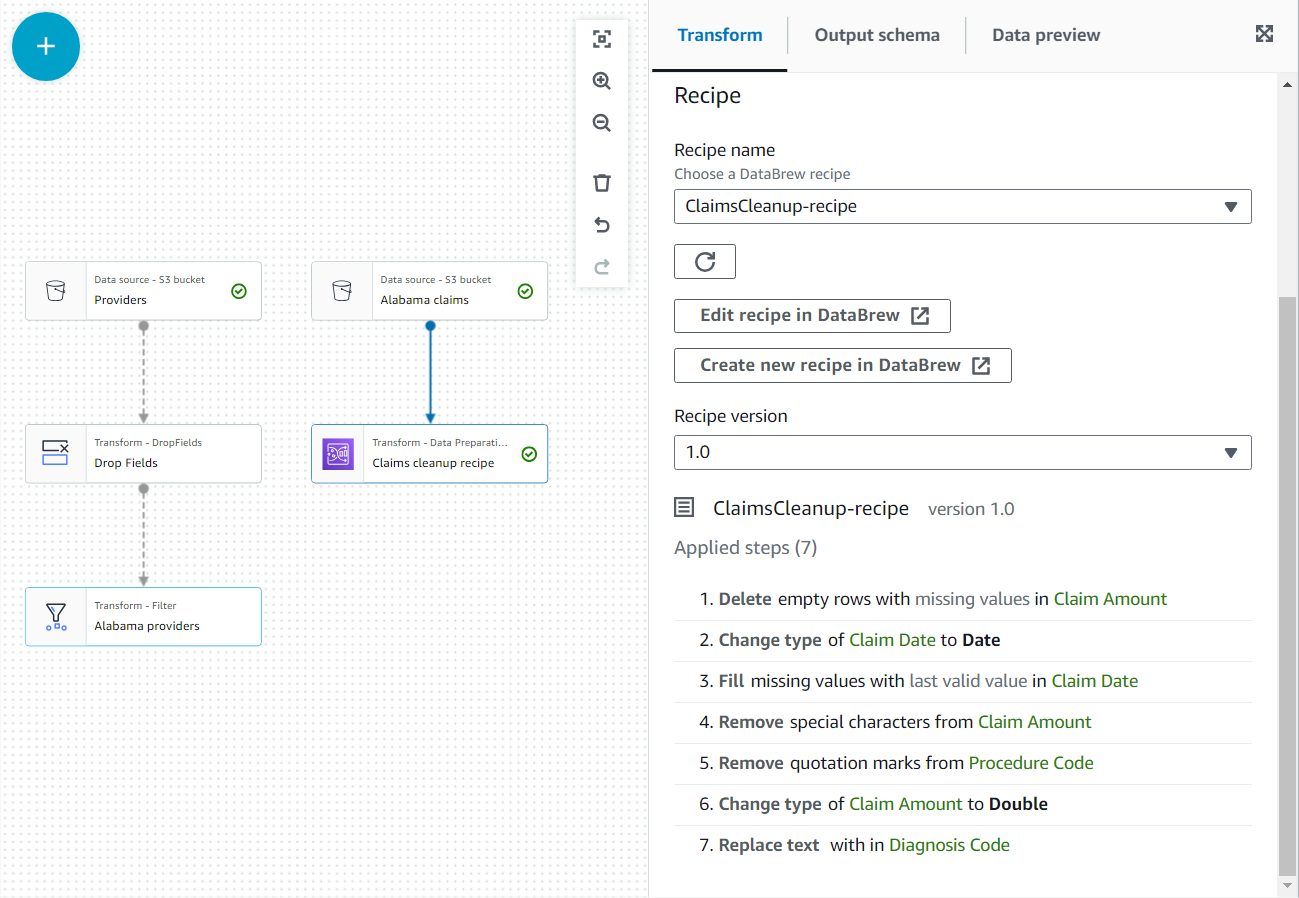
Glue Studioを使えば、GUIベースでETLジョブを構築することや、ジョブの実行、監視設定を行うことが可能です。
2.5. ワークフロー
ETLジョブ、クローラーを自動化し、データカタログ出力までの一連の処理をGUIで管理する機能です。
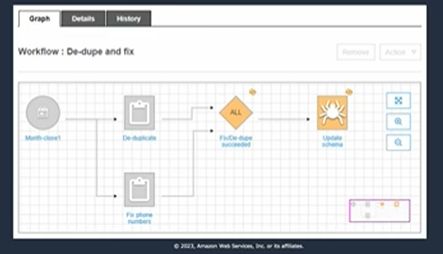
AWSには、ワークフロー系のサービスはほかにもあります。
- AWS Glue Workflow
- Glueワークフローは、基本的にデータの準備(ETL)を簡単に行うことを目的としたサーバーレスデータ統合サービスです。
- データの準備に必要なデータソースへの接続などを備えています。
- Glueジョブとの統合や連携のみの場合はこちらを選択するケースが考えられる
- AWS Step Functions
- 複数のAWSサービスを組み合わせてワークフローを構築できるサーバーレスオーケストレーションサービス
- ETLの処理も作成可能で、汎用性が高いワークフローを定義可能
- AWSサービスとの統合や連携を行うならばこちらを選択するケースが考えられる
- Amazon MWAA(Managed Workflows for Apache Airflow)
- OSSのApache Airflow
- オンプレからの移行で、すでにApache Airflowを使っている場合や、AWS以外との連携もある場合に選択するケースが考えられる
3.1. ブックマーク機能
ETLジョブを実行する場合、処理済みデータを記録し、差分抽出を可能にする機能です。 job.init()でブックマークの情報を取得し、job.commit()が呼び出されたときに状態を記録します。 そのため、ジョブスクリプトからjob.commit()が呼び出されていないと、ブックマーク機能を正常に利用できないことになります。
参考:エラー : ジョブのブックマークが有効なときにジョブがデータを再処理しています
3.2. Glue Streaming
Glueはもともとバッチ処理に特化したETLサービスという特徴があります。ただ、Glue Streamingを使うことで、準リアルタイム処理が可能になります。
具体的なユースケースは次のとおりです。詳細については、ドキュメントをご参照ください
- 不正検出
- ソーシャルメディア分析
- IoT分析
- ログの監視と分析
- レコメンデーションシステム
例えば、Amazon Kinesis Data StreamsとAWS Glue Streamingを連携することで準リアルタイムのデータ処理が実現できます。 Kinesis Data Streamsがデータソースとできるサービスと組み合わせることで、さまざまなユースケースに対応することができます。
3.3. Glue DataBrew
データのクリーニング、正規化、変換のためのフルマネージド型のビジュアルデータ準備サービスです。 null の削除、欠損値の置き換え、スキーマの不整合の修正、関数に基づく列の作成などが実施できます。
DataBrewは、S3に保存された以下のデータフォーマットをサポートしています。
- カンマ区切り値 (CSV)
- Microsoft Excel
- JSON
- ORC
- Parquet
3.4. ゼロETL統合
ETLのジョブやワークフローは大きな運用負荷が伴います。このようなものを極力抑えるようにできるのが、ゼロETL統合です。 ETLの要件によっては、完全になくすことができる可能性があります。
GlueのゼロETLのデータソースとして、主に次のようなものがあります。 参考:ゼロ ETL 統合
- AWS
- Amazon DynamoDB
- サードパーティー
- Salesforce
- Zendesk
- ServiceNow など
GlueのゼロETLのデータターゲットとして、主に次のようなものがあります。
- Amazon SageMaker Lakehouse
- Amazon Redshift
3.5. Glue Data Quality
データレイクのデータに対して、ユーザーが定義したルールに従って品質を自動的に測定し、統計などを表示してくれるマネージドサービスです。 これによって、データの変化を監視し、予想外の値が入ってくることを検知できます。
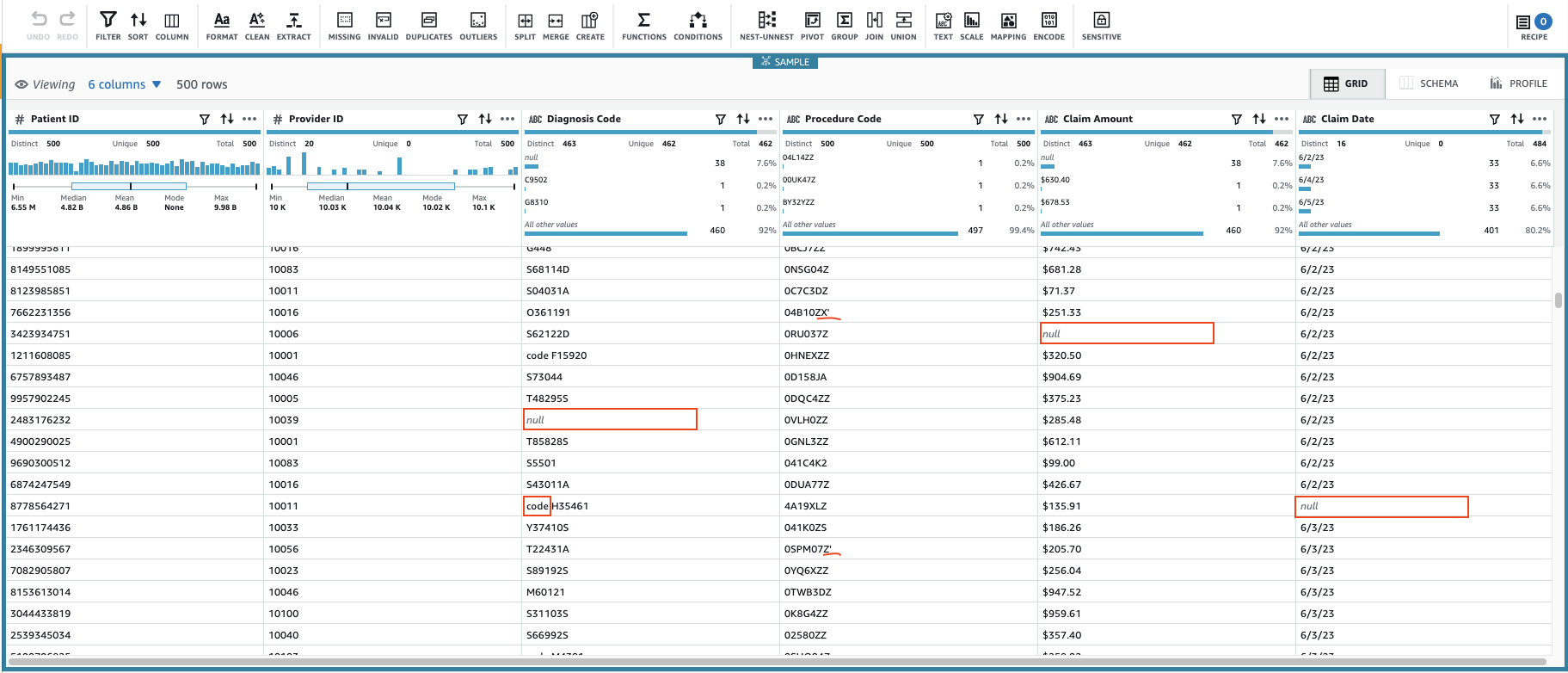
データ品質定義言語 (DQDL) を用いてカスタムルールを定義することによって、データの品質をチェックすることができます。
具体的には次のような記述を行うことでデータをチェックできます。詳細は、データ品質定義言語 (DQDL) リファレンスを参照してください。
Rules = [
IsComplete "order-id",
IsUnique "order-id"
]
以下の動画では、AWS Glue Data Qualityがどのようにデータ品質を管理するかについての基本的な説明や主要な機能について説明されています。 Measure and Monitor Data Quality of your Datasets in AWS Glue Data Catalog(YouTube) | Amazon Web Services

4.1. AWS Lake Formationとの連携
Lake Formationを利用すると、Glueが作成したデータカタログに対して詳細なアクセスコントロールを行うことができます。
具体的には、以下のアクセス管理を行うことができます。
- データベース、テーブルへのアクセス管理
- 列、行、または行列の組み合わせでのアクセス管理
アクセス管理の方法は、次の2つの方法があります。
- 名前付きリソースアクセスコントロール(NRAC)
- タグベースアクセスコントロール(TBAC)
- NRACよりも管理する権限が少なく、リソースが増えた場合の運用負荷が低いため、推奨される
詳細については、Lake Formation 許可の管理を参照してください。
4.2. コスト管理
コスト最適化については、スキャンするデータ量を最小限にすることと、処理時間に見合うサービス選択を意識することが重要であると考えます。 具体的には、以下のようなポイントを考慮します。
- ジョブブックマーク機能を用いて増分クロールを行い、処理時間を削減
- 必要なワーカータイプを選択しているか?過剰なDPUを割り当てていないか?
- 最小課金時間を下回る処理の場合、別の方法への変更を検討
また、コスト最適化については以下のAWSブログ記事をご参照ください
AWS Glue for Apache Spark のコストのモニタリングと最適化
4.3. モニタリング
AWS Glue のモニタリングは、以下のツールを利用することで実現できます。
- Amazon EventBridge
- ETLジョブの成功や失敗のイベントによって、次の処理を実行したり、SNSによる通知を実現
"detail-type":"Glue Job State Change"のイベントがSUCCEEDED、FAILED、TIMEOUT、STOPPEDに対して発生
- Amazon CloudWatch Logs
- ログファイルのモニタリングによる監視・通知
- Amazon CloudWatch メトリクス
- メトリクスによってジョブのリソース使用率(80%超)などを監視・通知
- AWS CloudTrail
- APIレベルでの実行を監視・通知
- 例えば、
DeleteCrawlerアクションが発生した場合に通知
4.4. セキュリティ
- アクセス管理
- IAMによってアクセス管理を実施
- 保管中のデータの暗号化
- AWS KMSを使用して以下を暗号化
- データカタログ
- ログ
- AWS KMSを使用して以下を暗号化
AWS Glueは、モダンなデータ統合基盤として、以下の特徴を提供します。
- サーバーレスでの運用による管理負荷の軽減
- 豊富な統合機能による開発効率の向上
- データ品質管理の自動化によるガバナンスの強化
これらの機能により、より価値の高いデータ分析に注力できる環境を実現できます。
詳しい内容については、AWS公式ドキュメントやAWS Black Belt Online Seminarをご参照ください。