本ページは、AWS に関する個人の勉強および勉強会で使用することを目的に、AWS ドキュメントなどを参照し作成しておりますが、記載の誤り等が含まれる場合がございます。
最新の情報については、AWS 公式ドキュメントをご参照ください。
標準的な SQL を使用して Amazon Simple Storage Service (Amazon S3) 内のデータを直接分析することを容易にするインタラクティブなクエリサービスです。
1.1. 公式ドキュメント
Amazon Athenaを理解する公式ドキュメントは次のとおりです。
1.2. 学習リソース
Athena をグラレコで解説||builders.flash
【AWS Black Belt Online Seminar】Amazon Athena(YouTube)(1:00:43)

第二十回 ちょっぴりDD -Amazon Athena であっちこっちのデータを一括分析しよう

第三十二回 ちょっぴりDD - Amazon Athena (Iceberg) x dbt ではじめるデータ分析!

1.3. ワークショップ
Amazon Athena Federated Query 経由で Amazon DynamoDB のデータを Amazon QuickSight で可視化するハンズオン
Amazon Athena ACID transaction workshop
CloudFront ハンズオン>Athena でのログ集計
AWS WAF を使って Web アプリケーションの防御を強化する>AWS WAF ログを調査する
1.4. 導入のメリット
Amazon Athenaを導入する主なメリットは以下の3つです。
- 標準SQLによる分析
- 既存のSQL知識を利用可能
- コスト最適化
- インフラ構築不要のサーバーレスサービス
- スキャンしたデータに応じた従量課金
- S3にあるデータを事前にロードする必要なく手軽に分析可能
- 大規模データに対しても高速なクエリを実施可能
1.4. 主なユースケース
- ログ分析
- CloudFrontのアクセスログ分析
- WAFのセキュリティ分析
- VPCフローログの通信分析
- データレイク分析
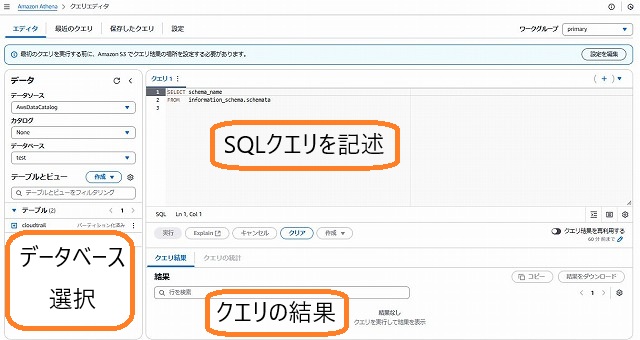
2.1. クエリエディタの画面構成
AWSマネジメントコンソール上で簡単にSQLを記述し、実行することができます。
2.2. データソース
基本となるデータソースは次の2つです。
- S3
- Athenaと異なるリージョンでも利用可能
- ただし、リージョン間の転送となるため、クエリパフォーマンスやコストに影響がある
- 異なるリージョンにするのは、リージョン間で移動できない理由がある場合のみを推奨
- AWS Glue Data Calalog
- Glueで作成されたデータカタログを使用可能
そのほかのデータソースコネクタを使用することで、次のようなものも接続できます。
- フェデレーテッドクエリを使用した外部データソース
- 外部の Hive メタストア
2.4. パーティション管理
Athenaはクエリでスキャンしたデータ量による従量課金であるため、スキャンするデータ量を制限できるようにすることは、コスト最適化の点で重要です。 スキャンするデータ量を制限する方法として、パーティションと呼ばれる一定のグループにデータを分けて整理しておくことで、目的のデータを探すのに読み込むデータを削減できます。 代表的なパーティションが、S3バケットのプレフィックスを年・月の単位にすることです。 具体的には、s3://amzn-s3-demo-bucket/hogehoge/ という単一のプレフィックスに保存するのではなく、s3://amzn-s3-demo-bucket/2025/01/ といったプレフィックスにして保存します。こうすることで、2025年1月のデータを読み込みたい場合、バケット全体から探す必要がなくなります。
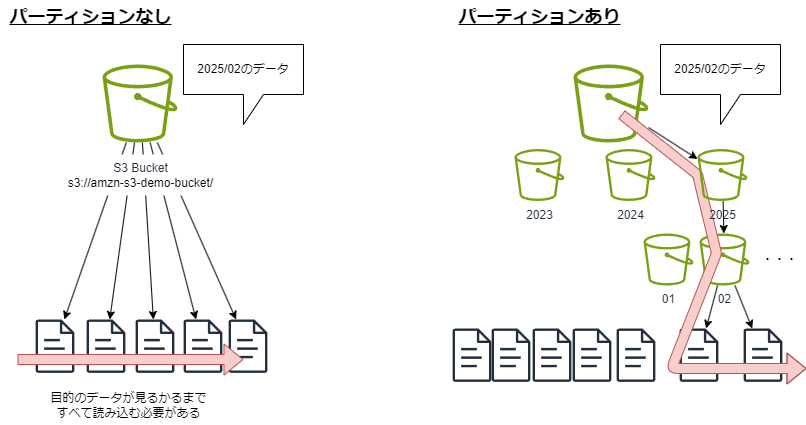
パーティションの分け方には2種類あります。
- Hive形式
s3://amzn-s3-demo-bucket/year=2025/month=01/day=01/myfile.csv- 新しいパーティションを追加するには
MSCK REPAIR TABLEが必要 - 自己説明的な構造(どこがyearなのか明確)
- Hive、Spark、EMRなどで利用するならば、互換性の高いHive形式を選択
- 非Hive形式
s3://amzn-s3-demo-bucket/2025/01/01/myfile.csvALTER TABLE ADD PARTITIONでパーティションを手動で追加できる- Hive形式よりURLが短くなる
S3バケットのプレフィックスでパーティション化したら、あとはAthenaでテーブルを作成します。 年(year)の範囲(range)にNOWを指定すると、範囲指定がクエリ実行時の年となるため、新しいパーティションを追加する手間がありません。
CREATE EXTERNAL TABLE my_test_table (
...
)
...
PARTITIONED BY (
year string,
month string,
day string
)
LOCATION "s3://amzn-s3-demo-bucket/test_table/"
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.year.type' = 'date',
'projection.year.format' = 'yyyy',
'projection.year.range' = '2024,NOW',
'projection.month.type' = 'integer',
'projection.month.range' = '1,12',
'projection.month.digits' = '2',
'projection.day.type' = 'integer',
'projection.day.range' = '1,31',
'projection.day.digits' = '2',
/* 非Hive形式 */
'storage.location.template' = 's3://amzn-s3-demo-bucket/test_table/${year}/${month}/${day}'
/* Hive形式
'storage.location.template' = 's3://amzn-s3-demo-bucket/test_table/year=${year}/month=${month}/day=${day}'
*/
);
2.5. テンプレートとビュー
過去に実行したクエリをテンプレートとして再利用可能な形で保存することができます。クエリエディタで実行したクエリ似たしいて、「名前をつけて保存」ができます。
詳細は、「保存されたクエリを使用する」を参照してください。
テンプレートは保存したクエリをそのまま実行する用途なのに対して、ビューはさらにデータの絞り込みや必要な項目のみにしたい場合に有効です。
作成するには、CREATE VIEWを使用します。
CREATE VIEW name_salary AS
SELECT
employees.name,
salaries.salary
FROM employees, salaries
WHERE employees.id = salaries.id
詳細は、「ビューを使用する」を参照してください。
3.1. フェデレーテッドクエリ
S3以外にあるデータソースに対してもクエリが実行できるようになります。 この機能を使うことで、複数のデータソースのデータを横断的に分析ができるようになります。
主なデータソースは次のとおりです。詳細はドキュメント「使用可能なデータソースコネクタ」を参照してください
- Amazon CloudWatch Logs
- Amazon DynamoDB
- Amazon DucumentDB
- Amazon RDS
動画:「Amazon Athena Federated Query」
動画: Amazon QuickSight で Amazon Athena フェデレーティッドクエリの結果を分析する
3.2. CTAS
CTASは、「シータス」と読みます。(AWS Black Belt Online Seminarより)
CREATE TABLE AS SELECT (CTAS) クエリは、SELECTステートメントの結果から、Athenaで新しいテーブルを作成します。作成されたテーブルのデータはS3に保存されます。
CTASを使うユースケースとしては次のようなものがあります
- 必要なデータのみが含まれるテーブルを作成
- クエリ結果を変換し、他のテーブル形式(Parquet、ORCなど)に移行してパフォーマンス向上
CTASの例
CREATE TABLE new_table
WITH (
format = 'Parquet',
write_compression = 'SNAPPY')
AS SELECT *
FROM old_table
WHERE condition;
3.3. 機械学習との統合
Amazon SageMaker AI を使用して Machine Learning (ML) 推論を実行する SQL ステートメントの記述に Athena を使用できます。
USING EXTERNAL FUNCTION ml_function_name (variable1 data_type[, variable2 data_type][,...])
RETURNS data_type
SAGEMAKER 'sagemaker_endpoint'
SELECT ml_function_name()
3.4. UDF(ユーザー定義関数)
レコードまたはレコードのグループを処理するためのカスタム関数を作成できます。
USING EXTERNAL FUNCTION UDF_name(variable1 data_type[, variable2 data_type][,...])
RETURNS data_type
LAMBDA 'lambda_function_name_or_ARN'
[, EXTERNAL FUNCTION UDF_name2(variable1 data_type[, variable2 data_type][,...])
RETURNS data_type
LAMBDA 'lambda_function_name_or_ARN'[,...]]
SELECT [...] UDF_name(expression) [, UDF_name2(expression)] [...]
3.5. ワークグループ
ワークグループとは、ユーザーやチームでクエリの実行やクエリ実行履歴の保存環境を分離できる仮想的なグループです。
ワークグループを使用すると、以下の管理ができます。
- IAMによるアクセス許可
- ワークグループごとのメトリクス管理
- データスキャン量やクエリ数をワークグループごとに把握可能
- ワークグループ単位でクエリ結果を保存するS3バケットの分離
- ワークグループごとにクエリ結果の暗号化を設定
- 同時に実行できるクエリの数やスキャン量の管理
- 指定したサイズ以上のデータスキャンをさせないようにできる
- 上限に達したことをSNS通知によって、想定外のコストが発生を検知可能
- ワークグループごとに分析エンジンタイプを指定
- Athena SQLかApache Sparkを指定し、制限可能
3.6. 地理空間データの分析
Athenaでは、ESRIの Java Geometry Libraryをサポートしています。
詳細は、「地理空間データをクエリする」、「例: 地理空間クエリ」を参照してください。
3.7. AWS CDKでの実装
実装例:ワークグループ作成のCDKコード(クリックしてください)
import { Construct } from 'constructs';
import * as cdk from 'aws-cdk-lib';
import {
aws_s3 as s3,
aws_athena as athena,
} from 'aws-cdk-lib';
export class AthenaStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// Athenaクエリ結果格納バケット
const athenaQueryResultBucket = new s3.Bucket(this, 'AthenaQueryResultBucket', {
bucketName: ['athena-query-result', accountId].join('-') ,
accessControl: s3.BucketAccessControl.PRIVATE,
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
objectOwnership: s3.ObjectOwnership.BUCKET_OWNER_ENFORCED,
encryption: s3.BucketEncryption.S3_MANAGED,
removalPolicy: props.isAutoDeleteObject ? cdk.RemovalPolicy.DESTROY : cdk.RemovalPolicy.RETAIN,
autoDeleteObjects: props.isAutoDeleteObject,
});
athenaQueryResultBucket.addLifecycleRule({
//expiration: cdk.Duration.days(60),
abortIncompleteMultipartUploadAfter: cdk.Duration.days(7), // 不完全なマルチパートアップロードの削除
transitions: [
{
storageClass: s3.StorageClass.INTELLIGENT_TIERING,
transitionAfter: cdk.Duration.days(0),
},
],
});
// Athena ワークグループ
const athenaWorkGroup = new athena.CfnWorkGroup(this,'athenaWorkGroup',{
name: ['athenaWorkGroup',accountId].join('-'),
description: 'description....',
workGroupConfiguration: {
resultConfiguration: {
outputLocation: `s3://${athenaQueryResultBucket.bucketName}/result-data`,
},
},
},
);
}
}
実装例:ALBログテーブル作成のCDKコード(クリックしてください)
const applicationLogsDatabase = new glue.CfnDatabase(scope, 'ApplicationLogsDatabase', {
catalogId: accountId,
databaseInput: {
name: 'application_logs_database',
},
});
// Glue Table (ALB Access Logs) with Partition Projection
const albAccessLogsTable = new glue.CfnTable(scope, "AlbAccessLogsTables", {
databaseName: 'application_logs_database',
catalogId: cdk.Stack.of(scope).account,
tableInput: {
name: 'alb_access_logs_table',
tableType: "EXTERNAL_TABLE",
parameters: {
"projection.enabled": true,
"projection.date.type": "date",
"projection.date.range": "NOW-1YEARS, NOW+9HOUR",
"projection.date.format": "yyyy/MM/dd",
"projection.date.interval": "1",
"projection.date.interval.unit": "DAYS",
"serialization.encoding": "utf-8",
"storage.location.template": `s3://amzn-s3-demo-bucket/AWSLogs/${cdk.Stack.of(scope).account}/elasticloadbalancing/${cdk.Stack.of(this).region}/` + "${date}/",
},
storageDescriptor: {
columns: [
{"name": "type","type": "string"},
{"name": "time","type": "string"},
{"name": "elb", "type": "string"},
{"name": "client_ip","type": "string"},
{"name": "client_port","type": "int"},
{"name": "target_ip","type": "string"},
{"name": "target_port","type": "int"},
{"name": "request_processing_time","type": "double"},
{"name": "target_processing_time","type": "double"},
{"name": "response_processing_time","type": "double"},
{"name": "elb_status_code","type": "int"},
{"name": "target_status_code","type": "string"},
{"name": "received_bytes","type": "bigint"},
{"name": "sent_bytes","type": "bigint"},
{"name": "request_verb","type": "string"},
{"name": "request_url","type": "string"},
{"name": "request_proto","type": "string"},
{"name": "user_agent","type": "string"},
{"name": "ssl_cipher","type": "string"},
{"name": "ssl_protocol","type": "string"},
{"name": "target_group_arn","type": "string"},
{"name": "trace_id","type": "string"},
{"name": "domain_name","type": "string"},
{"name": "chosen_cert_arn","type": "string"},
{"name": "matched_rule_priority","type": "string"},
{"name": "request_creation_time","type": "string"},
{"name": "actions_executed","type": "string"},
{"name": "redirect_url","type": "string"},
{"name": "lambda_error_reason","type": "string"},
{"name": "target_port_list","type": "string"},
{"name": "target_status_code_list","type": "string"},
{"name": "classification","type": "string"},
{"name": "classification_reason","type": "string"},
],
inputFormat: "org.apache.hadoop.mapred.TextInputFormat",
outputFormat: "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
serdeInfo: {
serializationLibrary: "org.apache.hadoop.hive.serde2.RegexSerDe",
parameters: {
'serialization.format': '1',
'input.regex': '([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) (.*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-_]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+?)\" \"([^\s]+)\" \"([^ ]*)\" \"([^ ]*)\"'
}
},
location: `s3://amzn-s3-demo-bucket/AWSLogs/${cdk.Stack.of(scope).account}/elasticloadbalancing/${cdk.Stack.of(this).region}`,
},
partitionKeys: [
{"name": "date", "type": "string"},
]
}
})
4.1. パフォーマンス
- スキャンデータ量を減らす
- 列指向フォーマットを利用
- データを圧縮
- パーティショニング
- ファイルサイズを一定以上にする
- 小さいファイルた大量にある場合はファイル操作のオーバーヘッドが発生するので、128MB以上にまとめる
- テーブルの結合を最適化
- 結合する場合は、大きいテーブルを左、小さいテーブルを右に記述する
Athenaでのパフォーマンスチューニングの詳細については、「Athena のパフォーマンスを最適化する」や「追加リソース」を参照してください。
4.2. モニタリング
- Amazon CloudWatch メトリクス
- AWS CloudTrail
4.3. セキュリティ
- データ保護
- AWS KMSによって暗号化
- アクセス管理
- AWS IAMによってアクセス制御を行います。
- 詳細は「Athena でのアイデンティティとアクセス権の管理」を参照してください
- データアクセス管理
- Lake Formationでデータへの詳細なアクセス管理が実施可能
Athenaは、データレイク戦略の中核として位置づけられ、S3に蓄積された様々な形式のデータを迅速に分析する強力なツールです。ETLパイプラインやダッシュボード構築などと組み合わせることで、データ駆動型の意思決定を促進するプラットフォームとして活用できます。 データ分析の需要が高まる中、Athenaはその柔軟性と拡張性により、ますます重要な役割を担っていくと思われます。